テープライトと100均製品で5m長のコーブ照明を作成
はじめに
天井に光を当てるタイプの間接照明をコーブ照明と呼ぶらしいです。
通常、折り上げ天井を用意する必要がありますが、
テープライトと100均の製品を使って5m長のコーブ照明を作ってみました。
ネットの海を漁ったところ、似たような作り方が見当たらなかったので、
使用した道具・材料と工程をメモしておきます。
先に成果物

道具・材料
マスキングテープ(ダイソー)
幅はできるだけ太めがいいです。
塗装用マスキングテープがおすすめです。
マスキングテープ(塗装用、白、30mm×12m)jp.daisonet.com
配線カバー(ダイソー)
今回は壁の色に合わせて白を使っています。
口径は11mmと16mmがあり、今回は11mmを使います。
今回は切らずに使用していますが、必要に応じて切断してください。
配線カバー(2本、50cm、口径11mm用、ホワイト)jp.daisonet.com
テープライト(switchbot)
switchbot製を使います。調光調色なのである程度自分好みの照明にできます。
今回は切らずに使用していますが、必要に応じて切断してください。

作業工程
はじめに
位置関係がややこしいので、先に完成品と図で整理します。

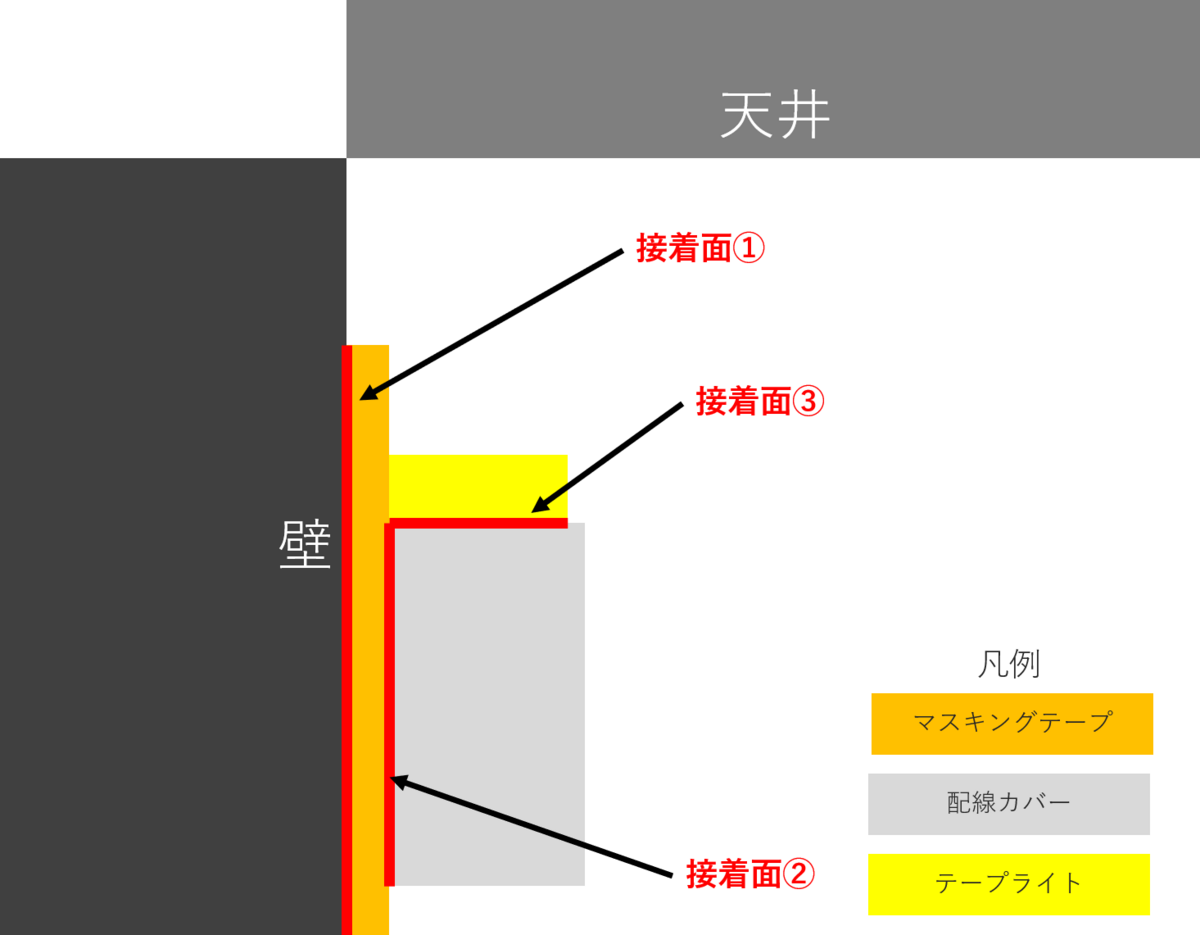
テープライトを天井に向け照らすことをゴールとし、
そのために配線カバーを利用しています。
下記では接着面①~③を取り付ける際のポイントを述べます。
取り付け予定位置にマスキングテープを貼り付ける(接着面①)
取り付け予定位置は天井から離れすぎていない、目線より上の箇所がいいでしょう。

マスキングテープの上に配線カバーを貼り付ける(接着面②)
マスキングテープの中心よりやや下部に貼り付けましょう。
上部に貼り付けてしまうとマステごと剥がれやすくなると思います。

配線カバーの上にテープライトを貼り付ける(接着面③)
テープライトの幅と配線カバーの奥行きはほぼ同じなので、ぴったり貼ることを心がけましょう。
点灯させる

後処理
テープライトの給電ケーブル部分も同じ配線カバーで隠しちゃいましょう。

おわりに
5m長の間接照明を4000円ほどで作ることができました。
switchbot製なのでAlexaも対応しており、音声操作が可能で便利です。
テープライトで間接照明を作りたいけど遮蔽物がない…という方は参考にしてみてください。
フレキシスポットの脚部にかなでものの天板を取り付けた
はじめに
フレキシスポットの脚にかなでものの天板を取り付けた話です。
使用した道具・材料と工程をメモしておきます。
以前はフレキシスポット純正の天板に木ネジで脚部を固定していましたが、
天板をかなでもの製の広いものに交換したいと思い、
ついでに鬼目ナットとボルトで固定するように施工しました。
先にbefore/after
before: D x W = 60cm x 120cm

after: D x W = 75cm x 140cm

道具・材料
天板
かなでもの製の「ラバーウッドアッシュ天板」にしました。
THE BOARD / ラバーウッド アッシュkanademono.design
サイズを1cm単位で指定でき、最大サイズはD x W = 80cm x 180cm です。
サイズをいくつにしても値段が変わらないので、大きいものほどお得だと感じました。
今回は面取りオプションR5をつけて、36,200円でした。


鬼目ナット
天板と脚部の固定に利用します。
脚部固定には全部で12個必要なので、下記で15個購入しました。
(リモコンパネルは移動を考えて両面テープで取り付けています)
サイズはM4で長さ10mmです。

ボルト
天板と脚部の固定に利用します。
M4サイズの8mm, 12mm を利用しました。
下記の商品はたくさん入っていて、個別で買うよりは安くつくと思います。

電動ドライバ
天板への穴あけ、およびネジやボルトの固定に利用します。
多分規格が統一されているので、どれを買っても同じだと思います。

電動ドライバ用ドリルアタッチメント
印をつけるのに1mmのドリルを、
下穴を開けるのに6mmのドリルを利用します。
今回は時間がなかったのでセットを下記で買いましたが、
最近はダイソーで1本ずつ売っているみたいです。

木工用ドリル刃6.0mm6角ビット付 | 【公式】DAISO(ダイソー)ネットストア
チタンコーティング鉄工ドリル刃2.0mm6角ビット付 | 【公式】DAISO(ダイソー)ネットストア
作業工程
準備
届いた天板を開封し、以前の天板から脚部を取り外します。
2つを並べた写真を撮りました。

天板に脚部をあて印をつける
取り付けたい位置に脚部を置き、固定穴の箇所にペンで印をつけ、中心に1mmのドリルで穴を開けておきます。(あとで下穴を開けるときの補助になります)
ここで、深く穴を開けてしまわないように、ドリルには1cmの部分がわかるようにマスキングテープで印をつけておきます。

ちなみに天板は若干ツルツルした面があるので、そちらが表になるように気をつけます。
天板に下穴を開ける
今度は印をつけた箇所に、6mmのドリルで下穴を開けます。
ペンで印をつけた幅を超えないように、なんとか頑張ります。
ここでも、深く穴を開けてしまわないように、ドリルには1cmの部分がわかるようにマスキングテープで印をつけておきます。
木くずが大量に出るので、掃除機を近くに配置しておいたほうがいいでしょう。

下穴に鬼目ナットを埋め込む
綿棒などを使って下穴に木工用ボンドを軽く塗布し、
六角のドライバで鬼目ナットを下穴に埋め込みます。
埋め込み加減は、穴に鬼目ナットがちょうど埋まるくらいです。

脚部を天板に固定する
下処理が済んだ天板に、脚部を乗せます。
脚部の固定穴から鬼目ナットが見える(と思う)ので、
ワッシャー挟んでボルトで固定します。(購入したボルトの頭が小さかったので、ワッシャーを噛ませないと抜けてしまいました。。ワッシャーがついててラッキーでした)

ひっくり返す
脚部の電源パーツを固定し、根性で机をひっくり返しておしまいです。
天板が広くなって満足しました!

おわりに
今回はフレキシスポットの脚にかなでものの天板を取り付けた話でした。
フレキシスポットの天板もいいのですが、サイズ展開は固定されていることがネックです。
自分好みの天板を取り付けたいときの参考にしてください。
複数アカウントのMoneyForwardから資産情報を取得して結合する方法で連携上限4件の縛りを突破する【docker, python, selenium, gspread】
はじめに
表題のことをやりたいです
【重要なお知らせ】当社サービス『マネーフォワード ME』は、2022年12月7日(月)より、無料会員の連携上限数を4件に変更することをお知らせします。変更の背景、今後のサービス提供および開発について以下よりご確認いただけます。何卒ご理解賜りますようお願い申し上げます。https://t.co/HISHBEITei pic.twitter.com/zHj0hpqQrQ
— 家計簿アプリ マネーフォワード ME (@MoneyForwardME) 2022年11月7日
2022/12/7 から無料会員アカウントでの連携上限数が10->4になるらしいです。
自分の連携数Xが 4 < X < 10 であり、総資産推移くらいしか見ないことから、
連携を複数アカウントに分散させ収集し結合すればいいじゃんと考えました。
過去に(無料連携数が10の頃に)1つのMoneyForwardアカウントから資産推移情報を持ってきてGoogleスプレッドシートに吐き出すところまで作っていたので、複数アカウントに対応することが今回のゴールになります。
↑ の記事を書いた頃からリポジトリ内容はだいぶ変わっており、いつの間にかdockerで動かすようになっています。
(前まで仮想ディスプレイとか設定が面倒でしたが、全部docker内でやることで何も考えなくてよくなりました…)
リポジトリはこちらです。
規約確認
複数アカウント利用が利用規約に抵触しないかが心配だったので、サポートに問い合わせてみました。
問い合わせ内容(記録が残っていないのでざっくり)
- 1個人による複数アカウントの利用は容認されているか
- 容認されない場合、どのように本人確認を実施し同一人物ではないと判定するのか
回答(原文ママ)
弊社サービスは、ご登録のメールアドレスでアカウントの管理を行っております。
このため、ご登録メールアドレス以外の「氏名、電話番号、住所」等の個人情報は
お預かりしておりません。
ご登録メールアドレスとパスワードにてログイン可能な仕組みのため、
確認されるアカウントを変更する際に、都度ログアウトのうえで、再ログインしていただく
形にはなりますが、複数アカウントをご利用いただくことは可能でございます。
個人で複数アカウントを使っていいよとの回答なので、今回の開発内容は現時点で問題なさそうです。
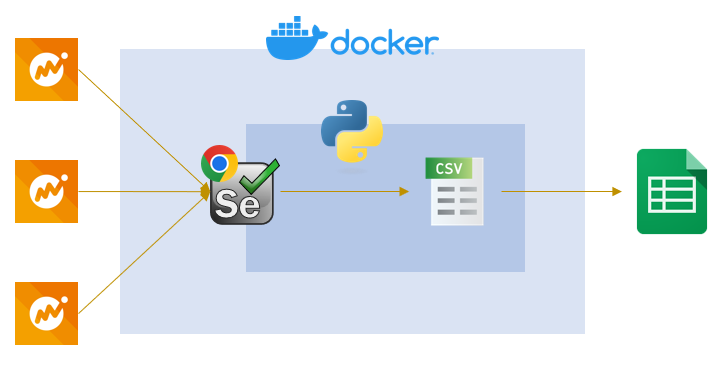
構成
全体こんな感じです。
簡単な図
実行後、ファイル構成はこんな感じになります。
├── README.md
├── Dockerfile
├── docker-compose.yml
├── make_env.sh
├── requirements.txt
├── download
├── log
│ └── log
├── csv
│ ├── all_history_with_profit_and_loss.csv ... アップロード用に過去の資産推移情報と統合したもの
│ ├── concat
│ │ ├── all_history_with_profit_and_loss.csv ... アカウント1~3の資産推移情報を集約したもの
│ │ ├── portfolio_det_depo.csv
│ │ ├── portfolio_det_eq.csv
│ │ ├── portfolio_det_mf.csv
│ │ └── portfolio_det_pns.csv
│ ├── <アカウント1>
│ │ ├── all_history.csv
│ │ ├── all_history_with_profit_and_loss.csv ... アカウント1の資産推移情報
│ │ ├── history
│ │ │ └── this_month.csv
│ │ └── portfolio
│ │ ├── portfolio_det_eq.csv
│ │ └── portfolio_det_pns.csv
│ ├── <アカウント2>
│ │ ├── all_history.csv
│ │ ├── all_history_with_profit_and_loss.csv ... アカウント2の資産推移情報
│ │ ├── history
│ │ │ └── this_month.csv
│ │ └── portfolio
│ │ └── portfolio_det_depo.csv
│ └── <アカウント3>
│ ├── all_history.csv
│ ├── all_history_with_profit_and_loss.csv ... アカウント3の資産推移情報
│ ├── history
│ │ └── this_month.csv
│ └── portfolio
│ └── portfolio_det_mf.csv
└── src
├── client_secret.json
├── config.ini
├── download_history.py
├── export_gspread.py
├── mf2gs.py
└── my_logging.py
(portfolio_**.csvが分かれているのは自分の例です)
src/config.ini で↓のように書いています。
[MONEYFORWARD] Email = [ "example1@hoge.com", "example2@hoge.com", "example2@hoge.com" ] Password = [ "password1", "password2", "password3" ] [SPREAD_SHEET] Key = 1_***** Worksheet_name = 資産推移データ(自動入力) [asset_depo] id = portfolio_det_depo column_name = sheet_name = _預金・現金・暗号資産 [asset_eq] id = portfolio_det_eq column_name = 損益_株式(現物) sheet_name = _株式(現物) [asset_mf] id = portfolio_det_mf column_name = 損益_投資信託 sheet_name = _投資信託 [asset_pns] id = portfolio_det_pns column_name = 損益_年金 sheet_name = _年金
前からの変更点
アカウントごとに収集してくるようにしました。
ここで、用語は下記のとおりです。
- 各月の資産推移 ... 名前の通り、各資産カテゴリごとの日別推移です。アカウントに登録して以降の情報をMoneyForwardは保持しています。
- 各assetの資産内訳(損益) ... 各資産ごとの詳細情報です。MoneyForwardは損益情報を当日分しか保持していません。
- そのため、資産推移と資産内訳(損益)を結合することで日ごとの損益情報をローカルcsvに保持します。
↓でcsv/<アカウント>/*.csvを収集・作成。
# download each files for email, password in zip(emails, passwords): mf = Moneyforward(email=email, password=password) try: mf.login() mf.download_history() # ... 各月の資産推移を取得し結合する for asset_id in [asset['id'] for asset in assets]: mf.get_valuation_profit_and_loss(asset_id) # ... 各assetの資産内訳(損益)を取得する mf.calc_profit_and_loss(assets) # ... 資産推移と資産内訳(損益)を結合 finally: mf.close()
↓で csv/<アカウントn>/*.csvからcsv/concat/*.csv を作成します。
*[!concat]と指定しないと結合したものを再計上しちゃうので気をつけないといけません(1敗)
結合方針は下記のとおりです。
- 資産推移 ... sumを取る
- 資産内訳(損益) ... axis=0で結合する
def concat_files(assets: list) -> Path: """ 複数アカウントから取得された資産推移と資産内訳(損益)を結合する Parameters ---------- assets : list of dict 各assetのidを含む辞書のリスト Returns ------- output_path : Path 各アカウント、各月、各assetの資産内訳(損益)を結合したcsvのパス """ concat_csv_dir = root_csv_dir / "concat" concat_csv_dir.mkdir(exist_ok=True, parents=True) ## asset files for asset in assets: df_list = [] for asset_csv_path in root_csv_dir.glob(f"*/portfolio/{asset['id']}.csv"): df = pd.read_csv(asset_csv_path, encoding="utf-8", sep=',') df_list.append(df) df_concat = pd.concat(df_list) df_concat.to_csv(concat_csv_dir / f"{asset['id']}.csv", encoding="utf-8", index=False) ## history files output_path = concat_csv_dir / "all_history_with_profit_and_loss.csv" df_concat = None for csv_path in root_csv_dir.glob(f"*[!concat]/all_history_with_profit_and_loss.csv"): df = pd.read_csv(csv_path, encoding="utf-8", sep=',') df.set_index('日付', inplace=True) df_concat = df_concat.add(df, fill_value=0) if df_concat is not None else df df_concat.sort_index(inplace=True, ascending=False) df_concat.to_csv(output_path, encoding="utf-8") return output_path
↓ でアップロード用の過去の情報と統合します。
なぜこんな処理があるかというと、今回の運用の都合上です。
- MoneyForwardはアカウントに登録して以降の資産情報しか保持しない
- 今回複数アカウントに分けて運用するため、新規アカウント登録が発生
- 各アカウントは過去情報を持っていないため、収集・結合とは別に統合が必要
統合処理を挟むことで、前時代(無料連携数が10の頃)に収集した情報を無駄にしなくて済みました。
pd.mergeするときhow='outer'にしていますが、同じキーのレコードを持つ場合に第1引数のdataframeが優先される仕様を今回はじめて知りました(1敗)
# concat each files new_all_history_wpl_csv_path = concat_files(assets) new_all_history_wpl = pd.read_csv(new_all_history_wpl_csv_path, encoding="utf-8", sep=',') # generate result csv all_history_wpl_csv_path = root_csv_dir / "all_history_with_profit_and_loss.csv" current_all_history_wpl = pd.read_csv(all_history_wpl_csv_path, encoding="utf-8", sep=',') if all_history_wpl_csv_path.exists() else new_all_history_wpl df_merged = pd.merge(new_all_history_wpl, current_all_history_wpl, how='outer') df_merged.drop_duplicates(subset='日付', inplace=True) df_merged.set_index('日付', inplace=True) df_merged.sort_index(inplace=True, axis='columns') df_merged.sort_index(inplace=True, ascending=False) df_merged.to_csv(all_history_wpl_csv_path, encoding="utf-8")
おわりに
MoneyForwardは便利ですが、これで資産推移グラフを見られるのでMoneyForwardに課金する必要がなくなりました
月500yenというのもチリツモなので...
あと、ソースに関数レベルでコメントをつけるようにしましたが、これがあれば解説書かなくていいじゃんと気づきました
MoneyForwardから取得した資産推移CSVをGsheetからいい感じに閲覧する
はじめに
昨日書いた記事でMoneyForwardから資産推移CSVを自動取得するところまで書きました. catdance124.hatenablog.jp
これをどうにかグラフ化してスマホから確認したいな~というところで選択肢は3つあります.
- WEBアプリとして実装,閲覧
- グラフをchatなどで送信
- スプレッドシートに書き込み,閲覧
簡単な方がいいよね...ということで3つ目のスプレッドシートに書き込み,閲覧の方向で実装しました.
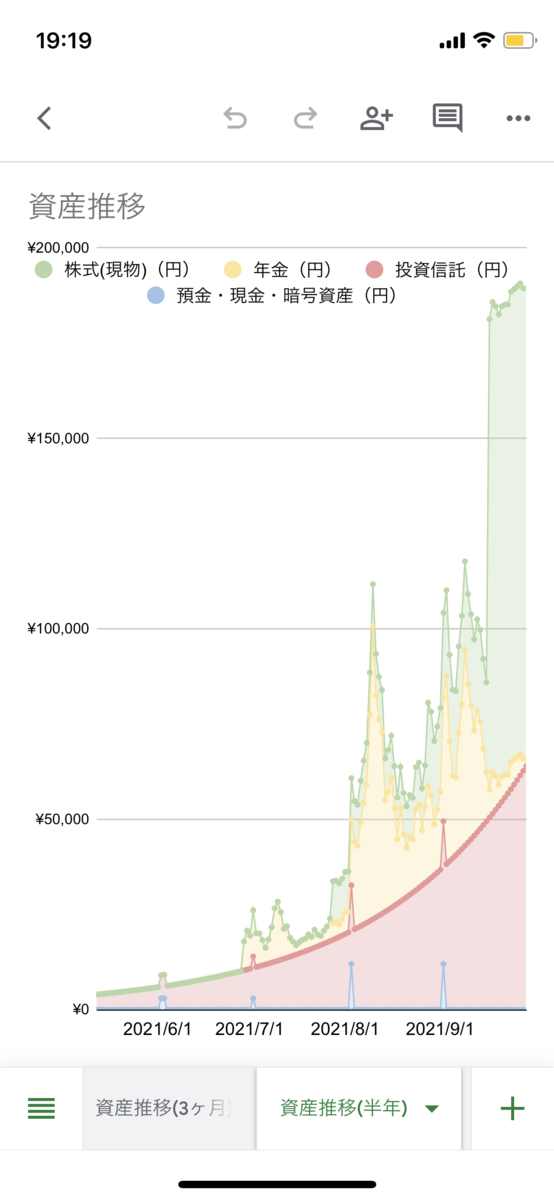
結果はこちら↓

スマホから見たグラフ

数値はでたらめですよ,もちろん😣
なお,いい感じのグラフ作成は下記記事を参考にしてさせていただきました. fire-hiko.com
この記事では
ことを説明します.
実装はこちら(昨日の記事でリポジトリを分けるといいましたが,あれは嘘でした)
CSVをスプレッドシートに書き込む
前述の記事でMoneyForwardから落としてきたall.csvをスプレッドシートに書き込むことを考えます.
まず,書き込むために色々準備が必要です. 下記記事を参考に準備しましょう.
順番通りやっていけば,jsonファイルが手に入るはずです.
このファイルをclient_secret.jsonとして保存しておきます.
あとは,書き込み先のシートのキーが必要です.
https://docs.google.com/spreadsheets/d/<ここの部分です>/edit
これをconfig.iniに書いておきます.
あとシートの名前も書いておきます.
# config.ini [SPREAD_SHEET] Key = 1_***** Worksheet_name = 資産推移データ(自動入力)
この設定を使ってpythonからスプレッドシートにall.csvを書き込んでみます.
短いのでベタ貼り↓
import configparser import csv import gspread from oauth2client.service_account import ServiceAccountCredentials def connect_gspread(json_path, spreadsheet_key): scope = ['https://spreadsheets.google.com/feeds','https://www.googleapis.com/auth/drive'] credentials = ServiceAccountCredentials.from_json_keyfile_name(json_path, scope) gc = gspread.authorize(credentials) workbook = gc.open_by_key(spreadsheet_key) return workbook def main(): config_ini = configparser.ConfigParser() config_ini.read('config.ini', encoding='utf-8') spreadsheet_key = config_ini.get('SPREAD_SHEET', 'Key') spreadsheet_worksheet_name = config_ini.get('SPREAD_SHEET', 'Worksheet_name') workbook = connect_gspread(json_path="client_secret.json", spreadsheet_key=spreadsheet_key) workbook.values_update( spreadsheet_worksheet_name, params={'valueInputOption': 'USER_ENTERED'}, body={'values': list(csv.reader(open("../csv/all.csv", encoding='shift-jis')))} ) if __name__ == "__main__": main()
もう書いてることそのままです.
スプレッドシートに接続して,設定にあるシート名のシートにlist化したcsvを貼り付けているだけです.
これで資産推移データの自動更新ができました.(あとはcronに登録などお好きに)
3ヶ月,半年,一年など各期間のシートを作成する
下記記事のスプレッドシートを参考に(コピペして)グラフを作成します.
fire-hiko.com
コピーさせていただき...

ペーストします

グラフを編集し

データ範囲を調整します

できたやつを「個別のシートに移動」させれば

見やすいグラフができあがります

これはデータを全件選択しているので,全期間ということになります.
半年で作成したければ,データ範囲を180にしたり,

3ヶ月で作成したければデータ範囲を90にすればOKです.
あとはスマホで見やすいようにレイアウトを微調整すれば完成です.
(数値はでたらめです)
おわりに
これでグラフを見られるのでMoneyForwardに課金する必要がなくなりました
月500yenというのもチリツモなので...
【Selenium+Python+CentOS7/Win10】MoneyForwardから資産推移CSVを自動取得
はじめに
表題のことをやりたかったです.
moneyforwardサブスク入ってないと資産推移グラフ見れないのが悔しいからseleniumでログインしてからcsv抜いてくるとこまで作った、あとはプロットすればいい感じになりそう📈
— kinosi (@catdance124) September 26, 2021
このツイートをしたときはWindowsで動かせていたのですが,レンタルサーバのCentOS7上で定期的に取得したかったので,対応しました.
本記事はそれらの説明です.
将来的には,このデータをいい感じにプロットして閲覧できるWEBページを作りたいと思います.
(もしくは画像化して配信)
成果物はこちら ↓.
github.com
環境構築について
seleniumとpandasをインストールしたり,ここは簡単
pip install selenium, pandas
web driverまわり
Windowsの場合はここからバイナリを落として来てそのまま使えます.かんたん.
https://sites.google.com/chromium.org/driver/
CentOS7でのweb driverを使用したアクセスが面倒だったのでメモを残します.
なぜCentOSでは面倒なのかというと,CLIから,つまりDisplayがないとMoneyForwardはアクセスを弾いちゃうらしいです.
Javascriptによるレンダリングがされていると,クライアントによってはレンダリングを実施しない場合があるらしいです.
そのため,chrome本体/chrome driver/仮想ディスプレイを入れる必要があります.
このあたりは下記記事を参考にさせていただきました.
CentOS7でSelenium+Pythonを動かすまで - Qiita
CentOS7とSeleniumとPythonとChromeで定期実行処理を作ってみた - Qiita
Chromeのインストール
# vim /etc/yum.repos.d/google.chrome.repo [google-chrome] name=google-chrome baseurl=http://dl.google.com/linux/chrome/rpm/stable/$basearch enabled=1 gpgcheck=1 gpgkey=https://dl-ssl.google.com/linux/linux_signing_key.pub
# yum update # yum -y install google-chrome-stable # google-chrome --version Google Chrome 94.0.4606.61 # yum -y install ipa-gothic-fonts ipa-mincho-fonts ipa-pgothic-fonts ipa-pmincho-fonts # google-chrome --headless --no-sandbox --dump-dom https://www.google.com/
Chromeドライバのインストール(バージョンをChromeに合わせる形で)
# cd /usr/local/bin # wget https://chromedriver.storage.googleapis.com/94.0.4606.61/chromedriver_linux64.zip # unzip chromedriver_linux64.zip # chmod 755 chromedriver # rm chromedriver_linux64.zip
仮想ディスプレイインストール&設定
# yum install xorg-x11-server-Xvfb
# vim /usr/lib/systemd/system/Xvfb.service
[Unit]
Description=Virtual Framebuffer X server for X Version 11
[Service]
Type=simple
EnvironmentFile=-/etc/sysconfig/Xvfb
ExecStart=/usr/bin/Xvfb $OPTION
ExecReload=/bin/kill -HUP ${MAINPID}
[Install]
WantedBy=multi-user.target
# vim /etc/sysconfig/Xvfb # Xvfb Enviroment File OPTION=":1 -screen 0 1366x768x24"
# systemctl enable Xvfb # systemctl start Xvfb
# export DISPLAY=localhost:1.0;
開発の流れ
GUIではどうやってCSVをダウンロードするかを確認
↓
seleniumでの記述に落とし込む
↓
落としてきたcsvをいい感じに整形
開発
GUIではどうやってCSVをダウンロードするかを確認
- URLアクセス

- [メールアドレスでログイン]を押す
- 遷移した先でメールアドレスを入力しsubmit
- 遷移した先でパスワードを入力しsubmit

- ログイン完了
- [資産推移]ページに移動(URLアクセス)

- ページ下部リンクから当月CSVをダウンロード
- 各月のページに飛び,CSVをダウンロード
こんな感じですかね.
勘のいい人は7,8の画像左下のリンクを見て,CSV取得はURL決め打ちでできるとわかったかと思います.
seleniumでの記述に落とし込む
細かい実装はリポジトリを見てもらうとして,上の記述をコードで追っていきます.
ログイン
ここの処理を実装します.
1. URLアクセス 2. [メールアドレスでログイン]を押す 3. 遷移した先でメールアドレスを入力しsubmit 4. 遷移した先でパスワードを入力しsubmit 5. ログイン完了
def login(self, email, password): login_url = "https://moneyforward.com/sign_in" self.driver.get(login_url) self.driver.find_element_by_link_text("メールアドレスでログイン").click() elem = self.driver.find_element_by_name("mfid_user[email]") elem.clear() elem.send_keys(email) elem.submit() elem = self.driver.find_element_by_name("mfid_user[password]") elem.clear() elem.send_keys(password) elem.submit()
ここはHTMLソースを見ながら要素のinnerHTMLやname, classなどが使えないかを見ながら,流れ通り実装していきます.
資産推移CSVダウンロード
6. [資産推移]ページに移動(URLアクセス) 7. ページ下部リンクから当月CSVをダウンロード 8. 各月のページに飛び,CSVをダウンロード
def download_history(self): # 6. [資産推移]ページに移動(URLアクセス) history_url = "https://moneyforward.com/bs/history" self.driver.get(history_url) elems = self.driver.find_elements_by_xpath('//*[@id="bs-history"]/*/table/tbody/tr/td/a') # download previous month csv # 8. 各月のページに飛び,CSVをダウンロード for elem in elems: href = elem.get_attribute("href") if "monthly" in href: month = re.search(r'\d{4}-\d{2}-\d{2}', href).group() save_path = Path(self.csv_dir/f"{month}.csv") if not save_path.exists(): month_csv = f"https://moneyforward.com/bs/history/list/{month}/monthly/csv" self.driver.get(month_csv) self._rename_latest_file(save_path) # download this month csv # 7. ページ下部リンクから当月CSVをダウンロード this_month_csv = "https://moneyforward.com/bs/history/csv" save_path = Path(self.csv_dir/"this_month.csv") if save_path.exists(): save_path.unlink() self.driver.get(this_month_csv) self._rename_latest_file(save_path)
大体は流れ通りなのですが,各月CSVをダイレクトにURLからダウンロードする場合,どの月のCSVが存在するかを判定しなければいけません.
そこは,資産推移ページに存在する各月のリンクhrefから情報を取得しています.href = elem.get_attribute("href")のところ
あとはダウンロードしたファイルの名前が日本語だったりで扱いづらいので,YYYY-MM-dd.csvにリネームしたりしています.
seleniumでは名前を付けて保存ができないので,一度ダウンロードしてからself._rename_latest_file(save_path) のところで最新日時ファイルをリネームするという処理をしています.
def _rename_latest_file(self, new_path): time.sleep(2) csv_list = self.csv_dir.glob('*[!all].csv') latest_csv = max(csv_list, key=lambda p: p.stat().st_ctime) latest_csv.rename(new_path)
落としてきたCSVをまとめる
各月で別のCSVになっているので,pandasでまとめます.
def _concat_csv(self): csv_list = sorted(self.csv_dir.glob('*[!all].csv')) df_list = [] for csv_path in csv_list: df = pd.read_csv(csv_path, encoding="shift-jis", sep=',') df_list.append(df) df_concat = pd.concat(df_list) df_concat.drop_duplicates(subset='日付', inplace=True) df_concat.set_index('日付', inplace=True) df_concat.sort_index(inplace=True) df_concat.fillna(0, inplace=True) df_concat.to_csv(Path(self.csv_dir/'all.csv'), encoding="shift-jis")
all.csv以外を読んで,concatして,日付でソート・重複削除後 all.csvとして保存するって感じです.
おわりに
MoneyForwardで資産推移グラフを見るためだけにお金を払いたくないというモチベーションのみで,着想からここまで3日でできました.
データを使用してプロットするプログラムは別リポジトリで作業しようと思っています.完走できるといいなあ
github.com
.
参考
【GAS】給料日の前倒し・後ろ倒し判定を実装する
はじめに
最近は基本的にはカード決済のみで生活できるようになってきました.
今のカード(楽天銀行デビットカード)はメールで使用金額を通知してくれたり,アプリから残高を確認できたりするのですが,自分のスマホでしか見れないので,頻繁に妻から今月あといくら残ってる?と聞かれて確認する流れになっています.
ということで,メールから使用金額を抜いて生活費(固定)から差っ引いた残高をLINEで通知しようと思いました.
もちろんGAS(Google Apps Script)実装ですね.無料なので.
成果物は下記のものです.
https://gist.github.com/catdance124/7c8e75470d35c05afce43424af63d947
実装上の問題点
生活費の区切りを給料日~翌給料日としていて,基本は25日~翌25日なのですが, 給料日が土日祝とかぶる場合,前倒しで支給されるというイレギュラーの発生に対応する必要があります.
解決策
25日が土日祝であればその前の土日祝でない日を返す関数を作成しました.(後ろ倒しの場合も同じ要領(-1を+1に)で可能だと思います)
土日祝かどうかを判定するisHoliday_()(丸パクリさせていただきました)をcalc_payday()から再帰的に呼び出し,一日づつずらしながら土日祝でない日を探します.
function isHoliday_(date) { // ref: https://moripro.net/gas-check-holiday/ // ①土日の判定 const day = date.getDay(); //曜日取得 if (day === 0 || day === 6) return true; // ②祝日の判定 const id = 'ja.japanese#holiday@group.v.calendar.google.com' const cal = CalendarApp.getCalendarById(id); const events = cal.getEventsForDay(date); //なんらかのイベントがある=祝日 if (events.length) return true; } function calc_payday(date) { if (isHoliday_(date)){ date.setDate(date.getDate() -1); return calc_payday(date); } else { return date; } }
使うときはこんな感じ,25日が日曜,23日が祝日であれば22日が帰ってくるはず
var DEFAULT_PAYDAY = 25; var message_date = message.getDate(); var default_payday = new Date(message_date); default_payday.setDate(DEFAULT_PAYDAY); var payday = calc_payday(default_payday);
おわりに
最近プライベートでコードをあまり書けてなかったんですが(ブログも),こういった実生活のちょっとしたところを円滑にするってのがやはり一番楽しいですね!
Inkscapeを使ってPowerPoint図をEPS画像に変換する
はじめに
そろそろ卒論修論の時期ですね...
その中でも図の作り方に苦労する人もいると思います.
今回は,タイトルにある通りPowerPointで作った図をTeX用eps画像に変換する簡単な手段を,Inkscapeのインストールから実際の使い方まで図付きで紹介します.
Inkscapeを使えばコマンドライン一発で変換できるので,一度環境を作ってしまえば楽々です.
環境
windows 10 poiwer point 2016 inkscape 1.0.1
参考にしたサイト
本題
Inkscapeのインストール
Draw Freely | Inkscape からインストーラを落としてきて実行しましょう.
基本的にはデフォルト設定で大丈夫ですが,後で楽するためにパスを通しておきましょう.

インストールが終わるとinkscapeのコマンドライン版inkscape.comが動くようになると思います.

PowerPointで図を作成し画像として保存
ここはいつも通りに図を作成します.
今回は図形と数式文字列が入っているこんな図を作ってみました.

図を保存するためにグループ化します.

グループ化できたら図として保存します.

保存形式はベクタ形式であるwmf,emf,svgが良いですが,後々の結果からsvgが最良だと思います.

Inkscapeでsvg->eps変換
svg画像がある場所でShift+右クリックからpowershellを開きます.

そこで下記コマンドを実行するだけです.
$ inkscape.com input_file_name.svg -o output_file_name.eps
すると変換されたeps画像ができあがりました.

latexから読み込んでみる
ちゃんとeps形式で表示されていることがわかります.

なお,先述したsvg形式で保存することが最良という点ですが,emf形式で保存すると数式が文字化けしてしまいました.
emf形式だとGUIの Inkscapeで読み込んでも文字化けしてしまっていたので,素直にsvg形式を選択するのが良さそうです.
なお,svgはOffice2016以降でしか扱えないことに注意してください.
ここでは下記記事を参考に構築したVSCode+latex環境を使用しました.
とても使いやすいのでここで感謝申し上げます.
qiita.com
ドラッグ&ドロップで変換できるようにする
いちいちコマンドで実行するのは面倒くさいですよね.
そこで簡単なバッチファイルを書いてみて,ドラッグ&ドロップで変換できるようにしてみましょう.
inkscape.comには次のような引数があります.これを使ってみましょう.
--export-type=[...] File type(s) to export: [svg,png,ps,eps,pdf,emf,wmf,xaml]
こんな感じでsvg->eps変換できます.ファイルネームは同じものが出力されます.
$ inkscape.com --export-type=eps .\Light_field_parameterization.svg
これを使ってconvert.batを書いてみます.
:: convert.batとして保存 inkscape.com --export-type=eps %1
これでconvert.batにsvg画像をドラッグ&ドロップすればその場にeps画像が保存されるようになりました.便利!
おわりに
今回はInkscapeを使ってPowerPoint図をEPS画像に変換する方法を紹介しました.
そろそろ卒論修論執筆しなきゃ...という人の助けになれば幸いです.