tensorflow2/kerasでcustom Convolutional LSTMを組み立てる
はじめに
時系列データを扱うNNとしてRNN(特にLSTM)が使用されています.
RNNは,その"reccurent"な構造により現時刻だけではなく前の時刻の情報を加味して推論できます.
ここで,時系列データとは,音声やテキストなど前後情報の並びに意味を持つデータです.
そして,画像+時間である動画などには,convolutional RNN(LSTM)が使用されます.
一般的にはconvolutional LSTM(convLSTM)*1がよく使用されており,
この内容については下記の資料がわかりやすいです.
www.slideshare.net
本記事ではtensorflow2/kerasを使ってカスタムconv LSTMレイヤーを作成することを目標とします.
本記事の構成
そもそもLSTM自体のカスタムについて,下記記事をとても参考にさせていただきました.
これを読んでから本記事を読むとわかりやすいかもしれません.
qiita.com
本記事も似たように構成されています.
環境
Windows10 CUDA Toolkit 10.1 update2 cuDNN v7.6.5 (November 5th, 2019), for CUDA 10.1 Python 3.6.6 (anaconda3) tensorflow 2.3.0 keras 2.4.3
オリジナルのconvLSTMを見てみる
下のような感じでConvLSTM2Dを呼び出すだけで使えますよね.
ここでは各フレーム (256,256,3) の動画を入力して同じフレーム長の特徴量を出力するようにしています.(return_sequences=True)
from tensorflow.keras.layers import Input, ConvLSTM2D from tensorflow.keras.models import Model inputs = Input((None, 256, 256, 3)) x = ConvLSTM2D(filters=64, kernel_size=3, padding='same', return_sequences=True)(inputs) model = Model(inputs=inputs, outputs=x) model.summary() # _________________________________________________________________ # Layer (type) Output Shape Param # # ================================================================= # input_6 (InputLayer) [(None, None, 256, 256, 3 0 # _________________________________________________________________ # conv_lst_m2d_4 (ConvLSTM2D) (None, None, 256, 256, 64 154624 # ================================================================= # Total params: 154,624 # Trainable params: 154,624 # Non-trainable params: 0 # _________________________________________________________________
これをConvRNN2Dを用いて書き換えてみましょう.
オリジナルのconvLSTMをConvRNN2Dを使って書き換えてみる
ConvRNN2Dはセルを渡すとそれをrecurrentにしてくれるものです.
セルを自分で定義してConvRNN2D() で囲むことで好きな構造のRNNを定義できます.
下記リンクはConvRNN2DではなくRNNですが...働き的にはほぼ同じです.
https://www.tensorflow.org/guide/keras/rnn
しかし,ConvRNN2Dはそのままimportできません;;
ソースを見るとわかりますが@keras_exportでデコレータされてないんですね~
from tensorflow.keras.layers import ConvRNN2D # --------------------------------------------------------------------------- # ImportError Traceback (most recent call last) # <ipython-input-11-ca860ffdc375> in <module>() # ----> 1 from tensorflow.keras.layers import ConvRNN2D # ImportError: cannot import name 'ConvRNN2D' # ---------------------------------------------------------------------------
なのでソースを引っ張ってきて無理やり呼び出します.
!wget https://raw.githubusercontent.com/tensorflow/tensorflow/v2.3.0/tensorflow/python/keras/layers/convolutional_recurrent.py
from tensorflow.keras.layers import Input from tensorflow.keras.models import Model from convolutional_recurrent import ConvRNN2D, ConvLSTM2DCell inputs = Input((None, 256, 256, 3)) # x = ConvLSTM2D(filters=64, kernel_size=3, padding='same', return_sequences=True)(inputs) x = ConvRNN2D(ConvLSTM2DCell(filters=64, kernel_size=3, padding='same'), return_sequences=True)(inputs) model = Model(inputs=inputs, outputs=x) model.summary() # _________________________________________________________________ # Layer (type) Output Shape Param # # ================================================================= # input_2 (InputLayer) [(None, None, 256, 256, 3 0 # _________________________________________________________________ # conv_rn_n2d (ConvRNN2D) (None, None, 256, 256, 64 154624 # ================================================================= # Total params: 154,624 # Trainable params: 154,624 # Non-trainable params: 0 # _________________________________________________________________
ConvLSTM2DをConvRNN2DとConvLSTM2DCellに分離して書けることがわかりました.
これで,ConvLSTM2DCellをいじることで好きなConvLSTMを作れます.
ConvLSTM2DCellを見てみる
実装を見る前にconvLSTMの処理を確認しておきます.
kerasではヒープホールは実装されていないので,ここでは触れません.
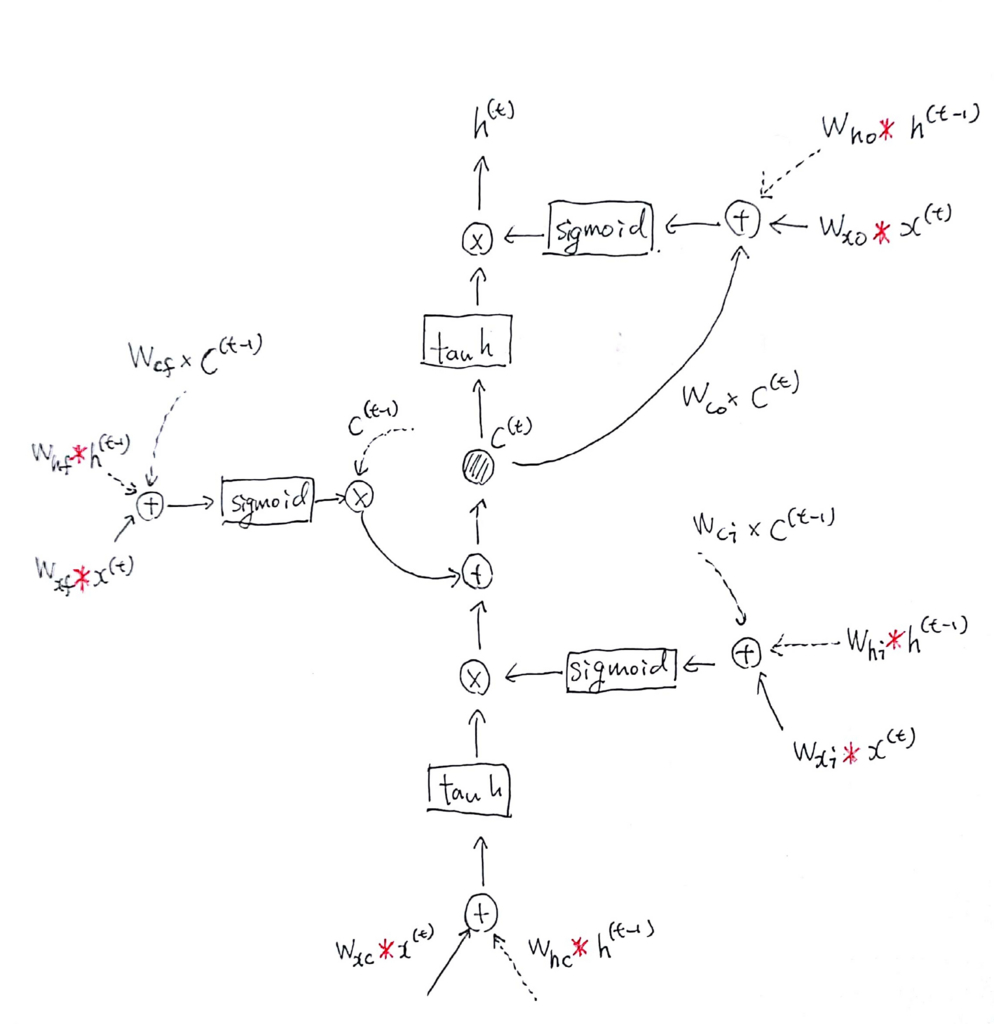
http://joisino.hatenablog.com/entry/2017/10/27/200000 より見やすい構造図をお借りしました.
ヒープホールを除いた部分を式で表すとこんな感じ.
入力と前時刻の状態に畳み込みを適用していることがわかります.
ConvLSTM2DCellの解読
上の式を踏まえて実装を見てみます.
tensorflow/convolutional_recurrent.py
build()で重みを定義しています.
def build(self, input_shape): if self.data_format == 'channels_first': channel_axis = 1 else: channel_axis = -1 if input_shape[channel_axis] is None: raise ValueError('The channel dimension of the inputs ' 'should be defined. Found `None`.') input_dim = input_shape[channel_axis] kernel_shape = self.kernel_size + (input_dim, self.filters * 4) self.kernel_shape = kernel_shape recurrent_kernel_shape = self.kernel_size + (self.filters, self.filters * 4) self.kernel = self.add_weight(shape=kernel_shape, initializer=self.kernel_initializer, name='kernel', regularizer=self.kernel_regularizer, constraint=self.kernel_constraint) self.recurrent_kernel = self.add_weight( shape=recurrent_kernel_shape, initializer=self.recurrent_initializer, name='recurrent_kernel', regularizer=self.recurrent_regularizer, constraint=self.recurrent_constraint) if self.use_bias: if self.unit_forget_bias: def bias_initializer(_, *args, **kwargs): return K.concatenate([ self.bias_initializer((self.filters,), *args, **kwargs), initializers.get('ones')((self.filters,), *args, **kwargs), self.bias_initializer((self.filters * 2,), *args, **kwargs), ]) else: bias_initializer = self.bias_initializer self.bias = self.add_weight( shape=(self.filters * 4,), name='bias', initializer=bias_initializer, regularizer=self.bias_regularizer, constraint=self.bias_constraint) else: self.bias = None self.built = True
self.add_weightに注目してみると,
入力に適用される重みが
self.kernelに,
前の状態に適用される重みが
self.recurrent_kernel,
バイアスが
self.biasに格納されていることがわかります.
上記のように,各4種類の重みが連結されたものがまとめて入っています.
そのため下記のようにフィルター数が4倍に設定されています.
kernel_shape = self.kernel_size + (input_dim, self.filters * 4)
self.kernel = self.add_weight(shape=kernel_shape,
...
call()がconvLSTMの本体部分です.
dropout関係のコードは省略しています.
コメントとして何が行われているのかを追記しています.
def call(self, inputs, states, training=None): # 前の状態を受け取る.h->前の隠れ状態,c->前のセル状態 h_tm1 = states[0] # previous memory state c_tm1 = states[1] # previous carry state # (略) # カーネル・バイアスをを4つに分けておく (kernel_i, kernel_f, kernel_c, kernel_o) = array_ops.split(self.kernel, 4, axis=3) (recurrent_kernel_i, recurrent_kernel_f, recurrent_kernel_c, recurrent_kernel_o) = array_ops.split(self.recurrent_kernel, 4, axis=3) if self.use_bias: bias_i, bias_f, bias_c, bias_o = array_ops.split(self.bias, 4) else: bias_i, bias_f, bias_c, bias_o = None, None, None, None # 上式中の畳み込み部分を先に処理する x_i = self.input_conv(inputs_i, kernel_i, bias_i, padding=self.padding) x_f = self.input_conv(inputs_f, kernel_f, bias_f, padding=self.padding) x_c = self.input_conv(inputs_c, kernel_c, bias_c, padding=self.padding) x_o = self.input_conv(inputs_o, kernel_o, bias_o, padding=self.padding) h_i = self.recurrent_conv(h_tm1_i, recurrent_kernel_i) h_f = self.recurrent_conv(h_tm1_f, recurrent_kernel_f) h_c = self.recurrent_conv(h_tm1_c, recurrent_kernel_c) h_o = self.recurrent_conv(h_tm1_o, recurrent_kernel_o) # 上式の計算を行い,h,cを更新する i = self.recurrent_activation(x_i + h_i) f = self.recurrent_activation(x_f + h_f) c = f * c_tm1 + i * self.activation(x_c + h_c) o = self.recurrent_activation(x_o + h_o) h = o * self.activation(c) # hを出力,[h,c]を次の時刻のセルに渡す return h, [h, c] def input_conv(self, x, w, b=None, padding='valid'): conv_out = K.conv2d(x, w, strides=self.strides, padding=padding, data_format=self.data_format, dilation_rate=self.dilation_rate) if b is not None: conv_out = K.bias_add(conv_out, b, data_format=self.data_format) return conv_out def recurrent_conv(self, x, w): conv_out = K.conv2d(x, w, strides=(1, 1), padding='same', data_format=self.data_format) return conv_out
return h, [h, c]部分を見てcall()は現時刻で出力するものと,次時刻に渡す状態を返していることがわかります.
ここをいじると自分で好きな構造のNNを作れそうです.
自分でカスタムconvLSTMを組み立てる
論文などで提案されている改良されたconvLSTMなどを自分で実装してみたいときの流れを紹介します.
今回対象とするconvLSTMの紹介
ここでは,[Zhang 2019]のCLSTM*2を構築したいと思います.


著者のpytorch実装も公開されているのでまだやりやすいですね.
ST-CLSTM/R_CLSTM_modules_2.py at master · hkzhang91/ST-CLSTM · GitHub
(論文の式と実装を見るとどことなく話が違う部分があるんですが)
(特にDは存在しなく,RがDの役割も担っています)
実装を元にこんな感じだな~と把握した構造が下図です.

実際に出力する値と次時刻のセルに渡す値が異なる点がポイントです.
出力する値は1チャンネルですが,引き継ぐ値は8チャンネルです.
そして,入力されるチャンネル数Cと合わせて,セル内ではC+8チャンネルのデータが処理されます.
なお,図中のRはCNNで,下図の構造をしています.

これを実装していきましょう.
実装だけみたい人は下記githubにあるので見てみてください.
github.com
状態はどれ?
今回のconvLSTMで前の時刻の情報を使っている部分はです.
はforget gateの変数と被ってしまうので便宜上
と表します.
重みはどれ?
式を見ると入力と前の状態をconcatしてから畳み込みをしていますが,ここでは従来どおり別々に畳み込みを行います.
重みとして定義するものは,
入力に適用される重み,前の状態に適用される重み
,バイアス
.
に加えて,R内の4つの畳み込みの重みです.
実装してみる
RefineNetの構築
まずはRを別のCNNRefineNetとして定義しておきます.
ここは特にLSTMとかは何も関係ないです.
class RefineNet(Layer): def __init__(self, hidden_states_chs=8): super(RefineNet, self).__init__() self.hidden_states_chs = hidden_states_chs self.kernel_initializer = 'glorot_uniform' self.kernel_regularizer = None self.kernel_constraint = None self.bias_initializer = 'zeros' self.bias_regularizer = None self.bias_constraint = None def build(self, input_shape): input_chs = input_shape[-1] # CLSTM's input_chs + hidden_states_chs self.bn1 = BatchNormalization() self.bn2 = BatchNormalization() self.refine_1_kernel = self.add_weight(name='refine_1_kernel', shape=(5, 5, input_chs, input_chs), initializer=self.kernel_initializer, regularizer=self.kernel_regularizer, constraint=self.kernel_constraint) self.refine_2_kernel = self.add_weight(name='refine_2_kernel', shape=(5, 5, input_chs, input_chs), initializer=self.kernel_initializer, regularizer=self.kernel_regularizer, constraint=self.kernel_constraint) self.refine_h_kernel = self.add_weight(name='refine_h_kernel', shape=(3, 3, input_chs, self.hidden_states_chs), initializer=self.kernel_initializer, regularizer=self.kernel_regularizer, constraint=self.kernel_constraint) self.refine_d_kernel = self.add_weight(name='refine_d_kernel', shape=(5, 5, input_chs, 1), initializer=self.kernel_initializer, regularizer=self.kernel_regularizer, constraint=self.kernel_constraint) self.refine_1_bias = None self.refine_2_bias = None self.refine_h_bias = self.add_weight(name='refine_h_bias', shape=(self.hidden_states_chs,), initializer=self.bias_initializer, regularizer=self.bias_regularizer, constraint=self.bias_constraint) self.refine_d_bias = self.add_weight(name='refine_d_bias', shape=(1,), initializer=self.bias_initializer, regularizer=self.bias_regularizer, constraint=self.bias_constraint) super(RefineNet, self).build(input_shape) def call(self, inputs): r_1 = self._conv(inputs, self.refine_1_kernel, self.refine_1_bias, padding='same') r_1 = self._BN_relu(r_1, self.bn1) r_2 = self._conv(r_1, self.refine_2_kernel, self.refine_2_bias, padding='same') r_2 = self._BN_relu(r_2, self.bn2) r_h = self._conv(r_2, self.refine_h_kernel, self.refine_h_bias, padding='same') r_d = self._conv(r_2, self.refine_d_kernel, self.refine_d_bias, padding='same') return r_h, r_d def _conv(self, x, w, b=None, padding='same'): conv_out = K.conv2d(x, w, strides=(1, 1), padding=padding, data_format='channels_last') if b is not None: conv_out = K.bias_add(conv_out, b, data_format='channels_last') return conv_out def _BN_relu(self, x, BN): x = BN(x) x = K.relu(x) return x def get_config(self): base_config = super(RefineNet, self).get_config() out_config = { **base_config, "hidden_states_chs": self.hidden_states_chs, "kernel_initializer": self.kernel_initializer, "kernel_regularizer": self.kernel_regularizer, "kernel_constraint": self.kernel_constraint, "bias_initializer": self.bias_initializer, "bias_regularizer": self.bias_regularizer, "bias_constraint": self.bias_constraint, } return out_config
convLSTMの重みを定義
次に本題のカスタムconvLSTMを実装します.
まず重み定義部分のbuild()です.
def build(self, input_shape): if self.data_format == 'channels_first': channel_axis = 1 else: channel_axis = -1 if input_shape[channel_axis] is None: raise ValueError('The channel dimension of the inputs ' 'should be defined. Found `None`.') self.input_dim = input_shape[channel_axis] kernel_shape = self.kernel_size + (self.input_dim, self.filters * 3 + self.input_dim) self.kernel_shape = kernel_shape recurrent_kernel_shape = self.kernel_size + (self.filters, self.filters * 3 + self.input_dim) self.kernel = self.add_weight(shape=kernel_shape, initializer=self.kernel_initializer, name='kernel', regularizer=self.kernel_regularizer, constraint=self.kernel_constraint) self.recurrent_kernel = self.add_weight( shape=recurrent_kernel_shape, initializer=self.recurrent_initializer, name='recurrent_kernel', regularizer=self.recurrent_regularizer, constraint=self.recurrent_constraint) if self.use_bias: if self.unit_forget_bias: def bias_initializer(_, *args, **kwargs): return K.concatenate([ self.bias_initializer((self.filters,), *args, **kwargs), initializers.get('ones')((self.filters,), *args, **kwargs), self.bias_initializer((self.filters,), *args, **kwargs), self.bias_initializer((self.input_dim,), *args, **kwargs), ]) else: bias_initializer = self.bias_initializer self.bias = self.add_weight( shape=(self.filters * 3 + self.input_dim,), name='bias', initializer=bias_initializer, regularizer=self.bias_regularizer, constraint=self.bias_constraint) else: self.bias = None self.refine_net = RefineNet(hidden_states_chs=self.filters) self.built = True
上図の構造を見るとわかりますが,このconvLSTMではi,f,cは8チャンネル出力,oは入力チャンネルCを出力します.
そのため,kernel及びreccurent kernel,biasの形状は下記のように設定されています.
kernel_shape = self.kernel_size + (self.input_dim, self.filters * 3 + self.input_dim) recurrent_kernel_shape = self.kernel_size + (self.filters, self.filters * 3 + self.input_dim) self.bias = self.add_weight( shape=(self.filters * 3 + self.input_dim,) ...
また,先程定義したCNNRefineNetをここで宣言しておきます.
convLSTMの処理部分を実装
オリジナルのconvLSTMと同じように,カーネルを分割し,処理どおりに計算していきます.
def call(self, inputs, states, training=None): h_tm1 = states[0] # previous memory state c_tm1 = states[1] # previous carry state # (略) (kernel_i, kernel_f, kernel_c, kernel_o) = array_ops.split(self.kernel, [self.filters,self.filters,self.filters, self.input_dim], axis=3) (recurrent_kernel_i, recurrent_kernel_f, recurrent_kernel_c, recurrent_kernel_o) = array_ops.split(self.recurrent_kernel, [self.filters,self.filters,self.filters, self.input_dim], axis=3) if self.use_bias: bias_i, bias_f, bias_c, bias_o = array_ops.split(self.bias, [self.filters,self.filters,self.filters, self.input_dim]) else: bias_i, bias_f, bias_c, bias_o = None, None, None, None x_i = self.input_conv(inputs_i, kernel_i, bias_i, padding=self.padding) x_f = self.input_conv(inputs_f, kernel_f, bias_f, padding=self.padding) x_c = self.input_conv(inputs_c, kernel_c, bias_c, padding=self.padding) x_o = self.input_conv(inputs_o, kernel_o, bias_o, padding=self.padding) h_i = self.recurrent_conv(h_tm1_i, recurrent_kernel_i) h_f = self.recurrent_conv(h_tm1_f, recurrent_kernel_f) h_c = self.recurrent_conv(h_tm1_c, recurrent_kernel_c) h_o = self.recurrent_conv(h_tm1_o, recurrent_kernel_o) i = self.recurrent_activation(x_i + h_i) f = self.recurrent_activation(x_f + h_f) c = f * c_tm1 + i * self.activation(x_c + h_c) o = self.recurrent_activation(x_o + h_o) h = K.concatenate((o, self.activation(c)), -1) r_h, r_d = self.refine_net(h) return r_d, [r_h, c]
下記がオリジナルのconvLSTMとは明確に異なる点です.
convLSTMのoutputをRに入力し,得られた1チャンネルの出力r_dをセル出力とし,8チャンネルの出力r_hをcとともに次の時刻のセルへ渡します.
h = K.concatenate((o, self.activation(c)), -1) r_h, r_d = self.refine_net(h) return r_d, [r_h, c]
実装したセルを使ってcustom convLSTMレイヤーを定義してみる
上でやったようにConvRNN2Dで囲ってやります.
こんな感じ
from tensorflow.keras.layers import Input from tensorflow.keras.models import Model from convolutional_recurrent import ConvRNN2D from STConvLSTM2DCell import STConvLSTM2DCell inputs = Input((None, 256, 256, 3)) x = ConvRNN2D(STConvLSTM2DCell(8, kernel_size=3, padding='same', activation='tanh', recurrent_activation='hard_sigmoid', kernel_initializer='glorot_uniform', recurrent_initializer='orthogonal'), return_sequences=True, name='STConvLSTM2D')(inputs) model = Model(inputs=inputs, outputs=x) model.summary() # _________________________________________________________________ # Layer (type) Output Shape Param # # ================================================================= # input_2 (InputLayer) [(None, None, 256, 256, 3 0 # _________________________________________________________________ # STConvLSTM2D (ConvRNN2D) (None, None, 256, 256, 1) 9914 # ================================================================= # Total params: 9,914 # Trainable params: 9,870 # Non-trainable params: 44 # _________________________________________________________________
セルの内部状態としては8チャンネル情報が循環していますが,出力としては1チャンネルであることが確認できます.
おわりに
この記事がtensorflow2/kerasでカスタムconvRNNを構築する人の助けになれば幸いです!
kerasは用意されたレイヤーを組み合わせるのは簡単なんですが,
レイヤーを自作するのはなかなかしんどいですね...
はやくtf.eagerかpytorchに移行しよう
全体のコードは下記githubに置いています.
興味があれば確認してみてください.
github.com
参考文献
*1:Xingjian Shi, et. al. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. In NIPS, 2015 https://arxiv.org/abs/1506.04214v1
*2:Zhang, Haokui, et al. "Exploiting temporal consistency for real-time video depth estimation." Proceedings of the IEEE International Conference on Computer Vision. 2019. https://openaccess.thecvf.com/content_ICCV_2019/html/Zhang_Exploiting_Temporal_Consistency_for_Real-Time_Video_Depth_Estimation_ICCV_2019_paper.html